
OpenAI Lanza GPT-4.5: ¿El Nuevo Modelo Marca un Antes y un Después en la IA Conversacional?
OpenAI ha lanzado GPT-4.5 como «Avance de Investigación». El nuevo modelo de lenguaje busca ser más natural y menos propenso a errores, aunque su coste es significativamente superior a sus predecesores.
OpenAI ha presentado GPT-4.5 en «vista previa de búsqueda», describiéndolo como su modelo más avanzado y completo para interacciones conversacionales. Esta nueva versión estará inicialmente disponible para usuarios y desarrolladores de ChatGPT Pro, con acceso extendido a usuarios Plus y Team la próxima semana.
GPT-4.5 representa una evolución basada en «aprendizaje no supervisado», diferenciándose del enfoque de «razonamiento» de modelos anteriores como o1. Mientras que modelos como o1 y o3-mini emplean un proceso de razonamiento previo a responder, GPT-4.5 responde de forma más directa, similar a un modelo de lenguaje clásico de gran escala, logrando mejoras en rendimiento a través del escalado tradicional de preentrenamiento.
Según OpenAI, GPT-4.5 (nombre clave Orion) es el modelo más grande que han desarrollado hasta la fecha. Rapha Gontijo Lopes, investigador de OpenAI, sugiere que la empresa «ha entrenado (probablemente) el modelo más grande del mundo». A pesar de su tamaño, OpenAI aclara en su documentación que GPT-4.5 no se considera un «modelo de frontera», posiblemente debido a la existencia de o3, un modelo interno que supera a GPT-4.5 en muchas áreas.
El precio de GPT-4.5 refleja sus altas demandas computacionales: 75 dólares por millón de tokens de entrada y 150 dólares por millón de tokens de salida. Esto lo sitúa como una opción significativamente más cara que GPT-4o (2,50$/10 $) u o1 (15 $/60 $). El equipo de OpenAI aún no ha confirmado si este modelo se ofrecerá a través de la API a largo plazo en esta configuración de precios. Al igual que su predecesor, mantiene una longitud de contexto de 128.000 tokens.
OpenAI anticipa que el razonamiento será una capacidad fundamental en futuros modelos y que las dos estrategias de escalado – preentrenamiento y razonamiento – se complementarán mutuamente. A medida que modelos como GPT-4.5 se vuelvan más inteligentes y ricos en conocimiento gracias al preentrenamiento, proporcionarán una base más sólida para el razonamiento y el desarrollo de agentes basados en herramientas. Sam Altman, CEO de OpenAI, ya anunció hace unas semanas que GPT-5 integrará estas dos capacidades.
GPT-4.5: Rendimiento Variable en Diferentes Pruebas
En las pruebas de referencia, GPT-4.5 muestra notables avances en áreas específicas. En la prueba SimpleQA, alcanza una precisión del 62,5%, superando significativamente el 38,2% de GPT-4o y el 43,6% del reciente Grok 3.
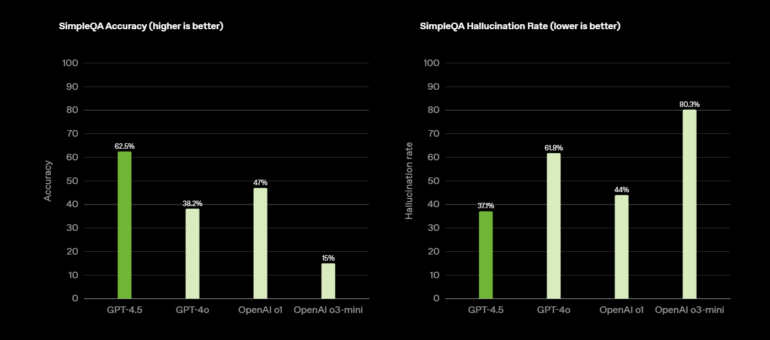
La tasa de alucinaciones (respuestas incorrectas o inventadas) disminuye del 61,8% al 37,1%, superando tanto a o1 como a o3-mini en este aspecto crucial. En las pruebas MMMLU (multilingüe) y MMMU (multimodal), GPT-4.5 también supera a sus predecesores GPT-4o (81,5% y 69,1%) y o3-mini (81,1% y NN) con puntuaciones del 85,1% y 74,4%, respectivamente.
En evaluaciones humanas, los evaluadores mostraron preferencia por GPT-4.5 frente a GPT-4o en todas las categorías evaluadas: inteligencia creativa (56,8%), preguntas vocacionales (63,2%) y preguntas de la vida diaria (57,0%).
Sin embargo, en benchmarks de áreas STEM (ciencia, tecnología, ingeniería y matemáticas), GPT-4.5 no logra superar a modelos de razonamiento como o3-mini. En GPQA (ciencias naturales), alcanza un 71,4%, mejorando el 53,6% de GPT-4o, pero aún por detrás de OpenAI o3-mini (79,7%). En AIME ’24 (matemáticas), GPT-4.5 alcanza el 36,7%, una mejora importante frente al 9,3% de GPT-4o, pero considerablemente inferior al 87,3% de o3-mini. En tareas de codificación, GPT-4.5 muestra un mejor rendimiento en la prueba SWE-Lancer Diamond, con un 32,6%, superando a GPT-4o (23,3%) y o3-mini (10,8%), aunque con un coste computacional significativamente mayor. En la prueba SWE-Bench Verified, alcanza un 38,0% frente al 30,7% de GPT-4o, pero se mantiene por debajo de o3-mini (61,0%).
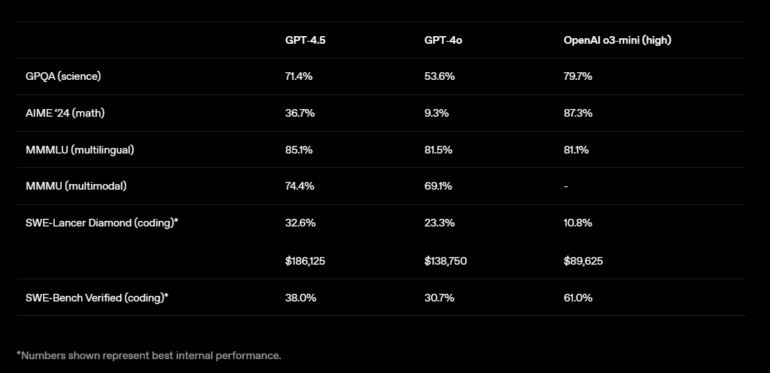
El reciente modelo Claude 3.7 Sonnet alcanza un 62,3% y un 70,3% respectivamente en benchmarks publicados por Anthropic. No obstante, es importante notar que estas cifras no son directamente comparables, ya que se utilizaron metodologías y conjuntos de problemas distintos. Por ejemplo, en el mapa del sistema para o3-mini, este modelo llegó a alcanzar un 49,3%.
En el benchmark independiente Aider, GPT-4.5 alcanza un 45%, significativamente superior al 23% de GPT-4o, pero aún por detrás de otros modelos. Sonnet 3.7 alcanza un 60% sin utilizar «razonamiento».
En resumen, los benchmarks no reflejan un salto de rendimiento masivo, siendo la prueba SimpleQA la que muestra los resultados más prometedores. Es probable que en los próximos días se genere un debate sobre si el escalado ha llegado a su límite, si el aprendizaje profundo ha encontrado un obstáculo, y cuándo el razonamiento podría enfrentar un destino similar.
GPT-4.5: Sensaciones Subjetivas y Mejoras Difusas
Sam Altman, CEO de OpenAI, quien recientemente se convirtió en padre, no participó en la presentación de GPT-4.5, pero comentó en X: «Es el primer modelo que me da la sensación de estar hablando con una persona reflexiva. He tenido varios momentos en los que me he sentado en mi silla y me ha sorprendido recibir consejos realmente buenos de una IA». Altman insiste en que GPT-4.5 no es un modelo de razonamiento y no romperá récords en benchmarks: «Es un tipo de inteligencia diferente y tiene una magia que nunca había sentido antes».
Por lo tanto, las mejoras parecen ser más a nivel de sensaciones que de resultados numéricos concretos en pruebas estandarizadas.
Andrej Karpathy, miembro fundador y ex empleado de OpenAI, comparte una percepción similar de progreso, aunque reconoce la dificultad para cuantificarlo. En sus comentarios sobre el lanzamiento, explica que cada incremento de 0,5 en el número de versión representa aproximadamente una multiplicación por diez en el cómputo de entrenamiento.
Karpathy describe la evolución de los modelos GPT desde GPT-1, que apenas generaba texto coherente, pasando por GPT-2 como un «juguete confuso», hasta GPT-3, que ofrecía resultados significativamente más interesantes. GPT-3.5 marcó el umbral de la comercialización e impulsó el «momento ChatGPT» de OpenAI.
Con GPT-4, las mejoras ya eran más sutiles, según Karpathy. «Todo era un poco mejor, pero de forma difusa», escribe. La elección de palabras era ligeramente más creativa, la comprensión de matices mejoraba, las analogías tenían un poco más de sentido, el modelo era ligeramente más divertido y las alucinaciones ocurrían con menor frecuencia.
Karpathy probó GPT-4.5 con expectativas similares, un modelo desarrollado con diez veces más cómputo de entrenamiento que GPT-4. Su conclusión: «Participo en el mismo hackathon que hace 2 años. Todo es un poco mejor y eso es genial, pero tampoco es algo tan drástico que salte a la vista de forma trivial».
En Clicategia, seguimos de cerca estos avances en la inteligencia artificial. GPT-4.5, con su enfoque en la naturalidad y la reducción de errores, podría abrir nuevas vías para la automatización de la comunicación y la creación de contenidos más humanos y efectivos en marketing digital. Estaremos atentos a su evolución y a las oportunidades que pueda ofrecer para nuestros clientes.



