
Meta ha presentado oficialmente los dos primeros modelos de su esperada serie Llama 4, marcando un hito importante en el desarrollo de arquitecturas multimodales construidas desde cero por la compañía.
Estos modelos iniciales, denominados Llama 4 Scout y Llama 4 Maverick, incorporan una arquitectura de Mezcla de Expertos (MoE). Esta innovadora técnica permite que solo un subconjunto de los parámetros del modelo se active para cada entrada, lo que reduce significativamente la carga computacional y mejora la eficiencia.
Según Meta, Llama 4 Scout y Llama 4 Maverick representan la primera generación de modelos Llama capaces de procesar de forma nativa tanto texto como imágenes dentro de una arquitectura unificada. La compañía destaca que estos modelos han sido entrenados con un vasto conjunto de datos de imágenes y vídeos para fomentar una comprensión visual general robusta. Durante la fase de preentrenamiento, el sistema demostró la capacidad de procesar hasta 48 imágenes simultáneamente. En evaluaciones posteriores, se confirmó un rendimiento óptimo con hasta ocho imágenes de entrada.
Llama 4 Scout: Multimodalidad Eficiente para Tareas con una Sola GPU
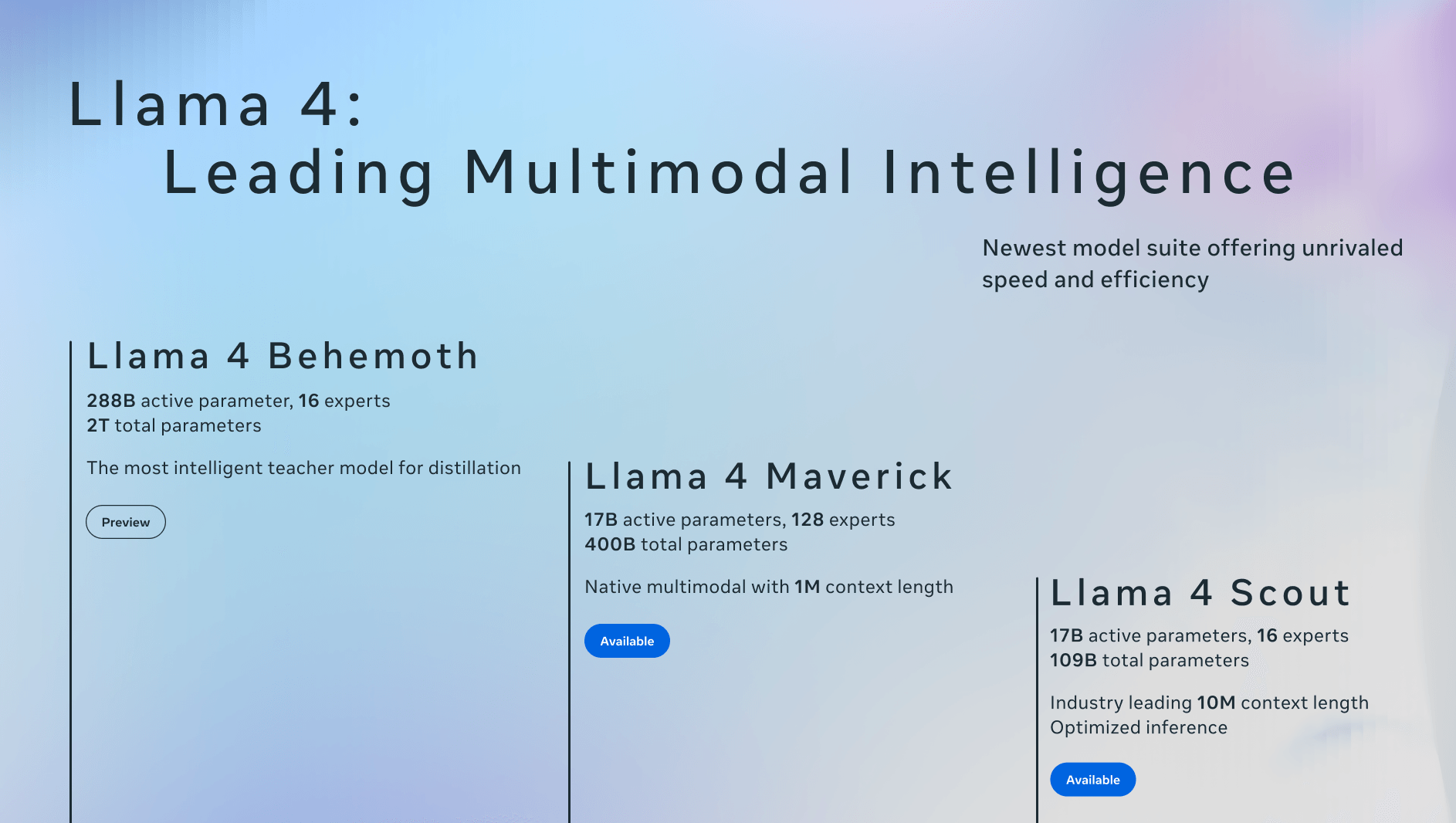
Llama 4 Scout, el modelo más pequeño de esta nueva familia, utiliza 17 mil millones de parámetros activos de un total de 109 mil millones, distribuidos entre 16 expertos. Su diseño ha sido optimizado para operar eficientemente en una sola GPU H100, lo que lo convierte en una opción ideal para tareas multimodales que requieren un rendimiento robusto sin demandar una infraestructura computacional masiva.
Scout se ha diseñado para abordar una amplia gama de tareas, incluyendo el procesamiento de textos extensos, la respuesta a preguntas basadas en información visual, el análisis de código y la comprensión de múltiples imágenes en contexto.
Un aspecto destacable de Scout es su ventana de contexto de 10 millones de tokens, lo que equivale aproximadamente a 5 millones de palabras. Esta extensa ventana contextual teóricamente permite al modelo procesar y comprender documentos y conversaciones de gran longitud. Sin embargo, Meta no ha proporcionado detalles sobre la eficiencia del modelo al manejar consultas complejas que requieran un análisis profundo del contexto, más allá de la simple búsqueda de palabras clave. La referencia al test «Aguja en el pajar» para evaluar la ventana de contexto sugiere que podrían existir limitaciones en la comprensión de información sutil o dispersa en textos largos.
Es importante señalar que, a pesar de la ventana de contexto de 10 millones de tokens, Llama 4 Scout fue entrenado con una longitud de contexto de solo 256K tokens durante las fases de preentrenamiento y postentrenamiento. La ventana de 10 millones de tokens reivindicada se basa en la generalización de la longitud de contexto, no en un entrenamiento directo con esa extensión.
Llama 4 Maverick: Escalabilidad y Alto Rendimiento Multimodal
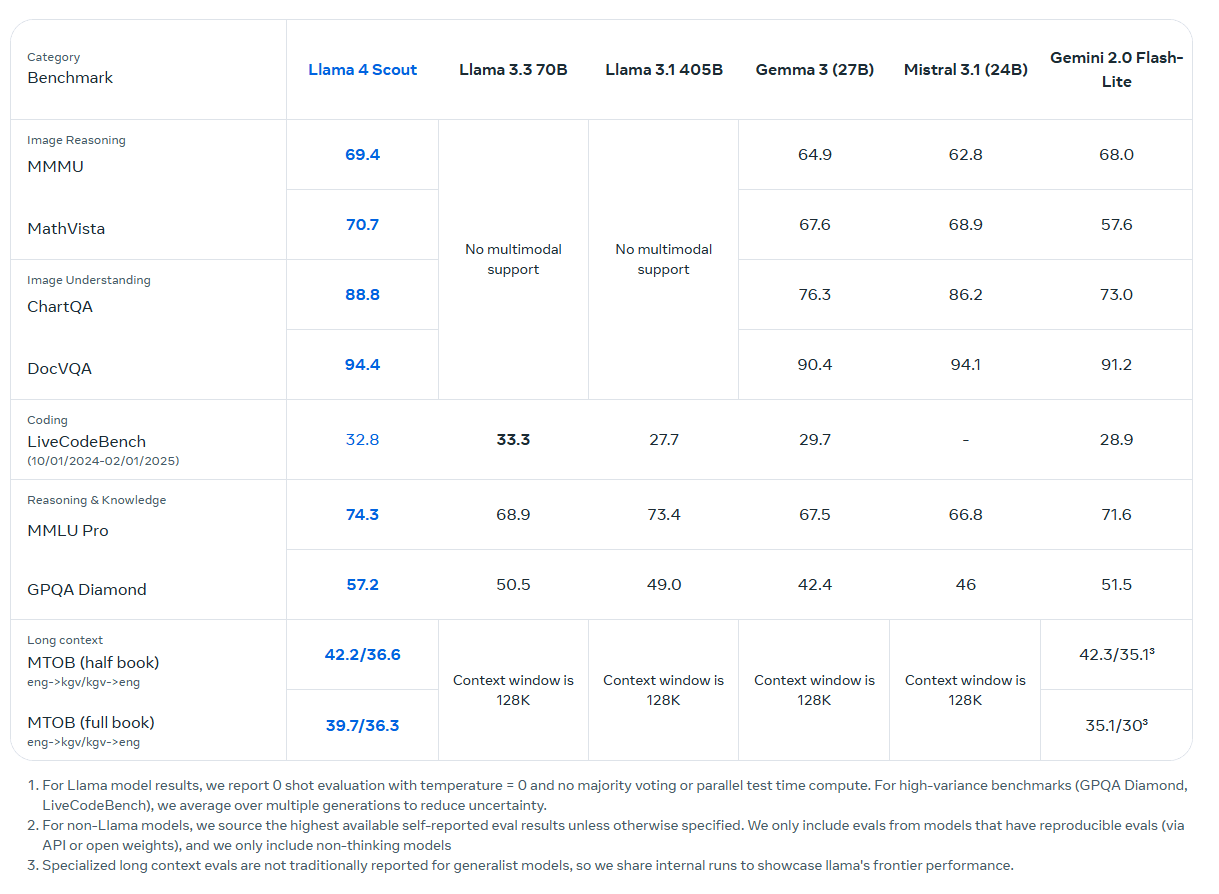
Llama 4 Maverick comparte con Scout la utilización de 17 mil millones de parámetros activos, pero los extrae de un conjunto total mucho mayor de 400 mil millones de parámetros, distribuidos entre 128 expertos. Al igual que Scout, Maverick se basa en una arquitectura de Mezcla de Expertos para optimizar la eficiencia computacional, activando solo un subconjunto de expertos para cada entrada.
A pesar de estas mejoras en eficiencia, la escala de Maverick requiere un host H100 completo para su despliegue. Maverick ofrece una ventana de contexto de hasta un millón de tokens, lo que sigue siendo considerablemente extenso para una amplia gama de aplicaciones.
Meta informa que Llama 4 Maverick supera a modelos de la competencia como GPT-4o de OpenAI y Gemini 2.0 Flash de Google en diversas evaluaciones comparativas multimodales. Además, en tareas de razonamiento y generación de código, Maverick presenta un rendimiento comparable al de Deepseek-V3, a pesar de utilizar menos de la mitad del número de parámetros activos. En pruebas experimentales de chat, Maverick ha alcanzado una puntuación de 1417 en la clasificación ELO de LMArena, lo que indica un rendimiento competitivo en interacciones conversacionales.
Tanto Llama 4 Scout como Llama 4 Maverick están disponibles como modelos de código abierto a través de llama.com y Hugging Face. Meta también ha integrado estos modelos en sus productos populares como WhatsApp, Messenger, Instagram Direct y Meta.ai.
Se anticipan más anuncios relacionados con la familia Llama 4 en el evento LlamaCon, programado para el 29 de abril. El registro para LlamaCon está disponible aquí.
Llama 4 «Behemoth»: El Modelo Maestro Detrás de Scout y Maverick
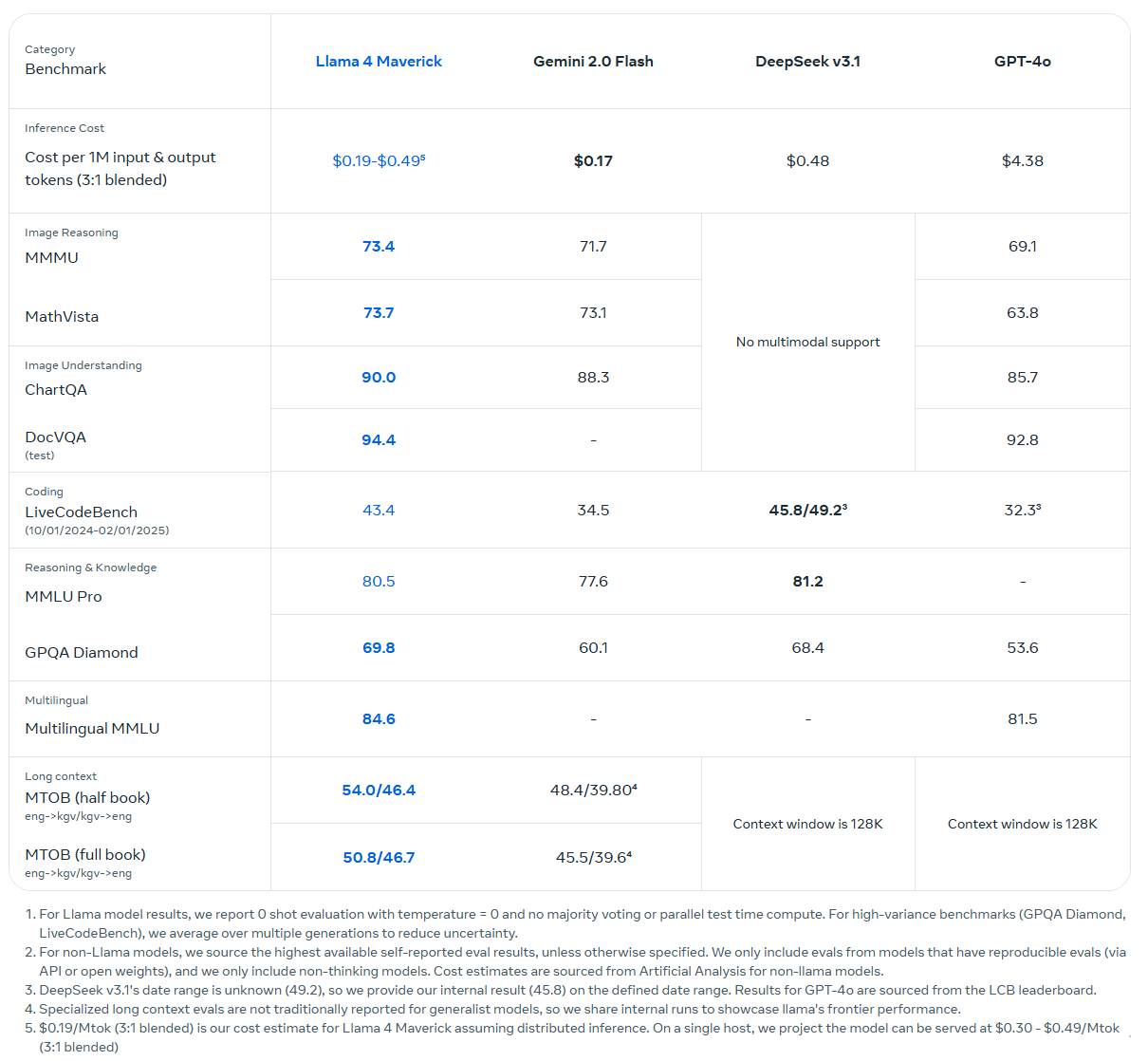
El entrenamiento de Llama 4 Scout y Maverick se llevó a cabo utilizando un modelo interno aún más grande y potente denominado Llama 4 Behemoth. Este modelo «maestro» cuenta con 288 mil millones de parámetros activos de un total de 2 billones, distribuidos entre 16 expertos. Behemoth actúa como un modelo de aprendizaje supervisado, y según Meta, supera a modelos líderes como GPT-4.5, Claude Sonnet 3.7 y Gemini 2.0 Pro en pruebas de matemáticas y ciencias.
Sin embargo, Meta no ha publicado una comparación directa con el modelo más reciente de Google, Gemini 2.5 Pro, que actualmente lidera las evaluaciones de razonamiento. Behemoth se encuentra aún en fase de entrenamiento y se espera su publicación en una fecha posterior. Aún no se ha anunciado un modelo Llama dedicado específicamente al razonamiento, aunque el CEO de Meta, Mark Zuckerberg, mencionó en enero que dicho modelo está en desarrollo.
Tras la fase inicial de preentrenamiento, Meta aplica una serie de etapas de postentrenamiento para optimizar el rendimiento de los modelos Llama 4. Estas etapas incluyen el ajuste fino supervisado utilizando ejemplos cuidadosamente seleccionados, seguido del aprendizaje por refuerzo en línea, implementando un nuevo sistema asíncrono que, según Meta, ha multiplicado por diez la eficiencia del entrenamiento.
Finalmente, se emplea la optimización directa de preferencias (DPO) para refinar la calidad de las respuestas generadas por los modelos, con un enfoque particular en la eliminación de ejemplos triviales o de baja calidad. Meta informa que más de la mitad del conjunto de entrenamiento de Maverick y el 95% del conjunto de entrenamiento de Behemoth se sometieron a un proceso de filtrado riguroso para enfocar los modelos en tareas más desafiantes y relevantes.
Restricciones en la UE para Modelos Multimodales Llama 4
Meta distribuye los modelos Llama 4 bajo su licencia estándar Llama, pero introduce una nueva restricción significativa: empresas y particulares con sede en la Unión Europea quedan excluidos del uso de los modelos multimodales. Esta limitación no se extiende a los usuarios finales, pero sí afecta a desarrolladores y organizaciones dentro de la UE.
Meta justifica esta decisión aludiendo a las «incertidumbres normativas» que rodean la legislación de la Unión Europea en materia de inteligencia artificial. Esta restricción refleja las tensiones existentes entre Meta y los reguladores de la UE, en un contexto donde Meta aboga por directrices más claras o regulaciones menos restrictivas, dependiendo de la interpretación de la normativa europea.
Para los desarrolladores fuera de la UE, se requiere mostrar una etiqueta visible de «Construido con Llama» y utilizar nombres de plantillas con el prefijo «Llama». Además, las plataformas con más de 700 millones de usuarios activos mensuales deben obtener un permiso especial de Meta para utilizar los modelos Llama 4.



