
Google está llevando su modelo de inteligencia artificial Gemini 2.5 Pro a un nuevo nivel con la introducción de un modo experimental llamado «Deep Think». Esta nueva funcionalidad está diseñada para dotar al modelo de capacidades de razonamiento más profundas y, además, incorpora la generación de audio nativa, abriendo un abanico de posibilidades para interacciones más ricas y naturales.
El modo «Deep Think» tiene como objetivo principal ayudar a Gemini 2.5 Pro a evaluar múltiples hipótesis y considerar diversas líneas de pensamiento antes de ofrecer una respuesta a una solicitud o «prompt» del usuario. Según Google, esta capacidad se basa en nuevos métodos de investigación interna y, por el momento, se está probando con un grupo limitado de usuarios de la API de Gemini.
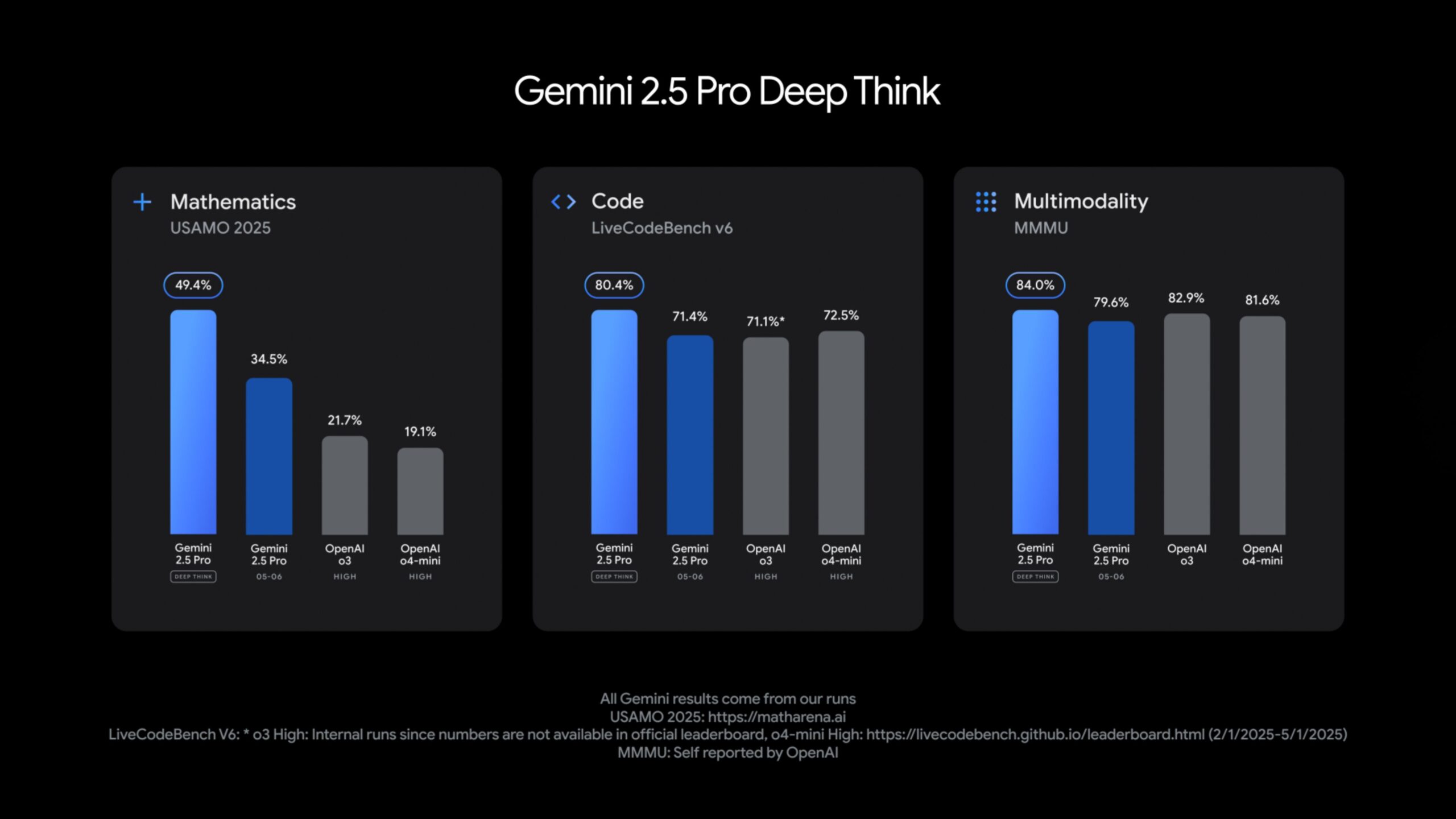
Google afirma que Gemini 2.5 Pro equipado con «Deep Think» ya supera al modelo o3 de OpenAI (presumiblemente una referencia a una versión avanzada o futura de sus modelos) en diversas tareas complejas. Entre ellas se incluyen pruebas de matemáticas de alto nivel como el USAMO 2025, el benchmark de programación LiveCodeBench y el MMMU, una prueba diseñada para evaluar el razonamiento multimodal (la capacidad de entender y procesar información de diferentes tipos, como texto e imágenes, de forma conjunta).
Además de las mejoras en Gemini 2.5 Pro, Google también ha actualizado su modelo Gemini 2.5 Flash, que está optimizado para ofrecer velocidad y eficiencia. La última versión de Flash presenta un mejor rendimiento en tareas de razonamiento, capacidades multimodales y generación de código, todo ello utilizando entre un 20 y un 30 por ciento menos de tokens para generar la misma salida. Esto se traduce en un modelo más rápido y económico para los desarrolladores.
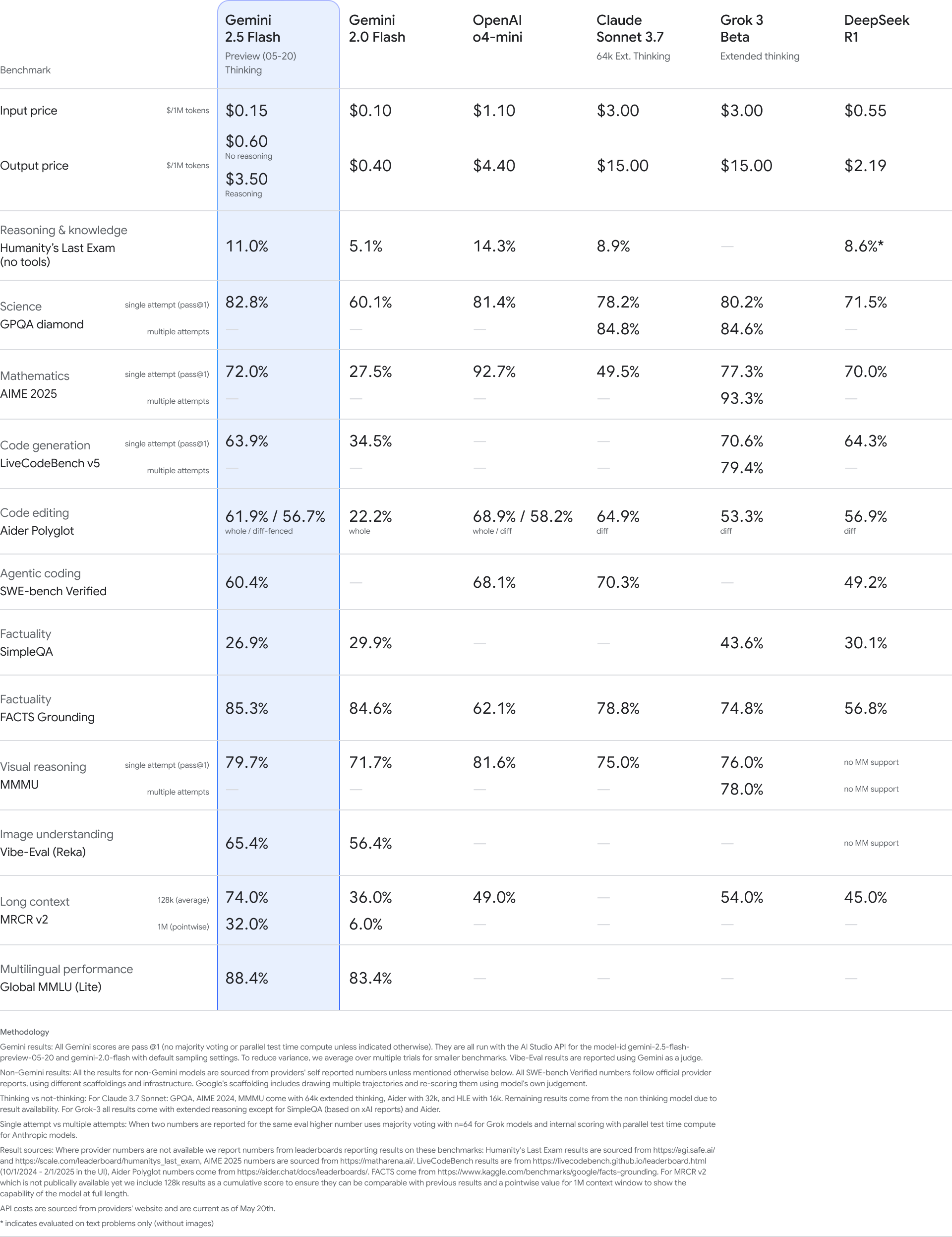
Gemini 2.5 Flash ya está disponible en plataformas como Google AI Studio, Vertex AI y la aplicación Gemini. Se espera que la disponibilidad general para su uso en producción llegue a principios de junio.
Nuevas Funciones de Audio y Control de Ordenadores: Interacciones Más Humanas y Mayor Integración
Una de las novedades más destacadas es que tanto Gemini 2.5 Pro como Flash ahora soportan la generación de voz a partir de texto (text-to-speech) de forma nativa, con múltiples perfiles de hablante disponibles. La salida de voz es capaz de capturar efectos sutiles como susurros y diferentes tonos emocionales, y es compatible con más de 24 idiomas. Los desarrolladores podrán controlar el acento, el tono y el estilo de habla a través de la API en tiempo real (Live API).
Para hacer las interacciones de voz aún más naturales y fluidas, Google ha introducido dos nuevas funciones:
- «Affective Dialogue» (Diálogo Afectivo): Permite al modelo detectar la emoción en la voz del usuario y responder de manera acorde, ya sea de forma neutral, empática o con un tono alegre. Esto busca crear conversaciones más humanas y menos robóticas.
- «Proactive Audio» (Audio Proactivo): Ayuda a filtrar las conversaciones de fondo, de modo que la IA solo responda cuando se le dirige directamente. El objetivo es reducir las interacciones accidentales y hacer que el control por voz sea más fiable y preciso en entornos ruidosos o con múltiples hablantes.
(Nota: Aquí originalmente había un vídeo de YouTube incrustado demostrando estas funciones)
Además, Google está integrando características del Proyecto Mariner en la API de Gemini y en Vertex AI. Esto permitirá al modelo controlar aplicaciones de ordenador, como un navegador web, abriendo la puerta a la automatización de tareas complejas directamente desde la interfaz de IA.
Para los desarrolladores, Gemini ahora incluye «resúmenes de pensamiento» (thought summaries), que ofrecen una vista estructurada del razonamiento interno del modelo y las acciones que toma para llegar a una respuesta. Para gestionar el rendimiento y los costes, los desarrolladores también podrán configurar «presupuestos de pensamiento» (thinking budgets) para limitar o deshabilitar la cantidad de tokens que el modelo utiliza para el razonamiento en tareas específicas.
La API de Gemini también ha añadido soporte para el Protocolo de Contexto de Modelo (MCP) de Anthropic, lo que podría facilitar la integración con herramientas de código abierto y fomentar un ecosistema de IA más interoperable. Google está explorando la posibilidad de alojar servidores MCP para apoyar el desarrollo de aplicaciones basadas en agentes.
Gemma, el Modelo de Código Abierto de Google, se Vuelve Multimodal
Google también ha ampliado su línea de modelos de inteligencia artificial de código abierto con el lanzamiento de Gemma 3n. Se trata de un modelo ligero, diseñado específicamente para funcionar de manera eficiente en dispositivos móviles como smartphones, tablets y ordenadores portátiles. Este modelo se basa en una nueva arquitectura desarrollada en colaboración con importantes fabricantes de hardware, incluyendo Qualcomm, MediaTek y Samsung.
Gemma 3n está optimizado para ofrecer potentes capacidades multimodales manteniendo un bajo consumo de recursos. Las versiones de 5B y 8B (5 mil y 8 mil millones) de parámetros requieren solo de 2 a 3 GB de RAM, lo que las hace ideales para aplicaciones que se ejecutan directamente en el dispositivo del usuario (on-device), sin necesidad de una conexión constante a la nube.
(Nota: Aquí originalmente había un vídeo de YouTube incrustado sobre Gemma 3n)
El modelo es capaz de procesar texto, audio e imágenes, y puede realizar tareas como transcripción, traducción y procesamiento de entradas mixtas que combinan diferentes modalidades. Una característica clave de Gemma 3n es «Mix-n-Match«, que permite a los desarrolladores extraer sub-modelos más pequeños de la arquitectura principal, adaptándolos a casos de uso específicos y optimizando aún más el rendimiento y el consumo de recursos.
Google también ha mejorado las capacidades multilingües de Gemma 3n, con un enfoque particular en idiomas como el alemán, japonés, coreano, español y francés. Ya está disponible una versión preliminar del modelo a través de Google AI Studio y el AI Edge Toolkit para el desarrollo local en dispositivos.
En Clicategia, seguimos de cerca estos avances en inteligencia artificial porque entendemos el impacto transformador que tienen y tendrán en el marketing digital y en la forma en que las empresas interactúan con sus clientes. La capacidad de los modelos de IA para razonar más profundamente, interactuar de forma más natural a través de la voz y operar directamente en dispositivos móviles abre nuevas vías para la personalización, la automatización y la creación de experiencias de usuario innovadoras. Si quieres saber cómo estas tecnologías pueden impulsar tu negocio, no dudes en contactarnos.



